Running on AWS
Let's see how easy it is to run fseval jobs on AWS. We are going to do this using the Ray launcher from Hydra. We are going to take the quick start example and run it on an AWS cluster. Specifically, EC2.
Prerequisites
We are going to use more or less the same configuration as we did in the Quick start example. Again, start by downloading the example project: running-on-aws-using-ray.zip
Installing the required packages
Now, let's install the required packages:
pip install hydra-ray-launcher --upgrade
pip install ray[default]==1.13.0
We require Ray version 1.13 and up, because it contains a fix regarding protobuf that is necessary for our setup.
Authenticating to AWS
Make sure you are authenticated to AWS. Ray uses either the environment variables or your AWS profile stored in ~/.aws (run aws configure to install a profile) to read your authentication details. Make sure you have the AWS V2 installed.
You can test your authentication as follows:
aws sts get-caller-identity
✓ which should give you some output.
✕ if this does not yet work, see AWS's elorate guide on authenticating the CLI for more info: AWS CLI Configuration basics.
Experiment setup
In the experiment, we configured the main config file like so:
defaults:
- base_pipeline_config
- _self_
- override dataset: synthetic
- override validator: knn
- override /callbacks:
- to_sql
- override hydra/launcher: custom_ray_aws
n_bootstraps: 1
callbacks:
to_sql:
url: sqlite:////home/ubuntu/results/results.sqlite # any well-defined database URL
Here, we are configuring to use a new launcher called custom_ray_aws.
defaults:
- ray_aws
env_setup:
pip_packages:
fseval: 3.0.3
ray:
cluster:
# Mount our code to the execution directory on both the head- and worker nodes.
# See: https://docs.ray.io/en/master/cluster/vms/references/ray-cluster-configuration.html#cluster-configuration-file-mounts
file_mounts:
/home/ubuntu: benchmark.py
initialization_commands:
- mkdir -p /home/ubuntu/results
sync_down:
source_dir: /home/ubuntu/results
target_dir: .
In this launcher config, a lot of stuff is happening. In short:
fsevalis installed on the EC2 cluster nodeOnce a node has been started,
benchmark.pyis mounted into the home folder. Ray by default runs all experiments from this folder. This is such that we can correctly instantiate any classes that were defined in the config as a_target_.noteIf you would like to explore with a terminal inside a node, try setting
stop_cluster: falseincustom_ray_config.yaml, run an experiment, and then connect to your EC2 instance with SSH.An initialization command is run to make sure the
/home/ubuntu/resultsdirectory exists. We configured our SQLite table to be stored inside this folder.Finally, once the experiment has been finished, download everything inside of
/home/ubuntu/resultsto the current working directory (.).
Running the experiment
python benchmark.py --multirun ranker='glob(*)'
Now, the experiment should start running, on AWS! Ray automatically instantiates and configures nodes on EC2, ships your code, installs fseval, and runs the experiments. Cool!
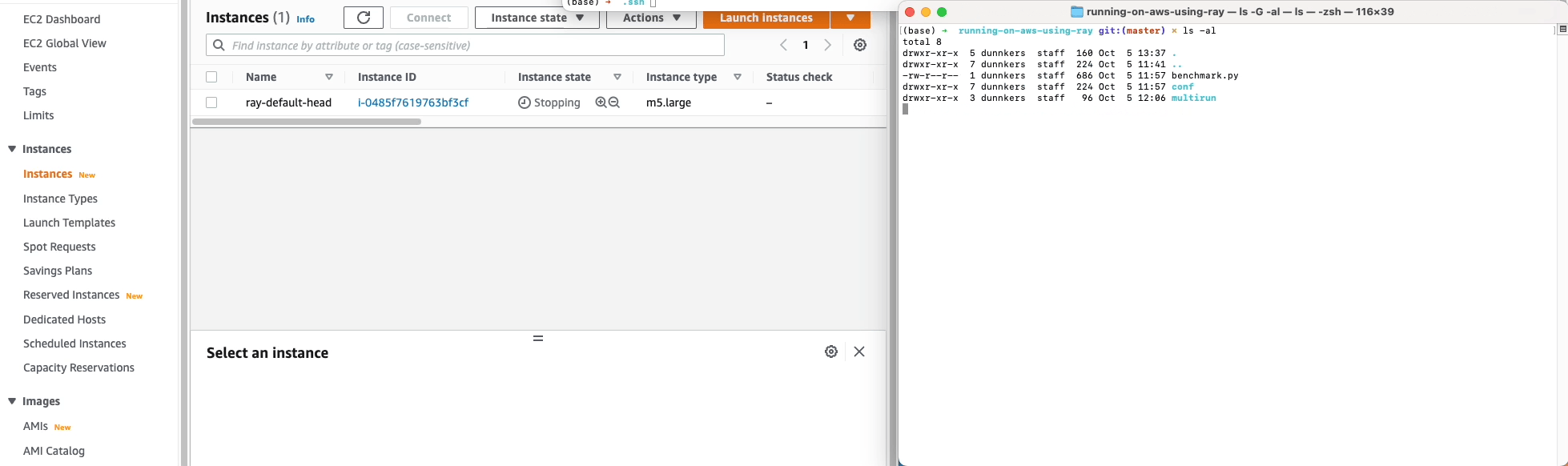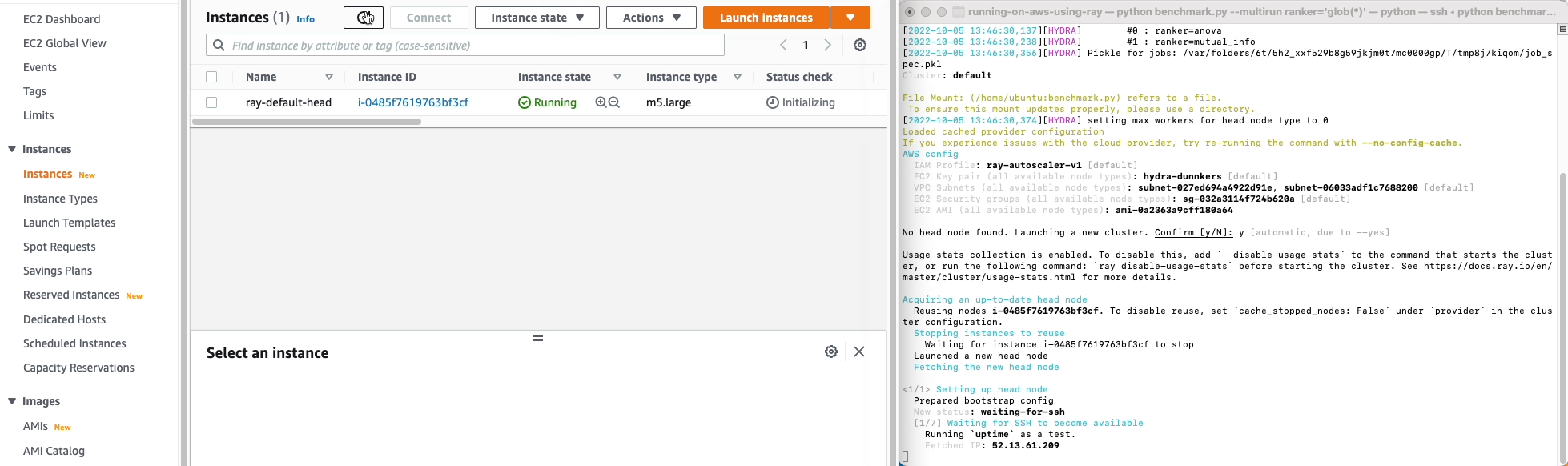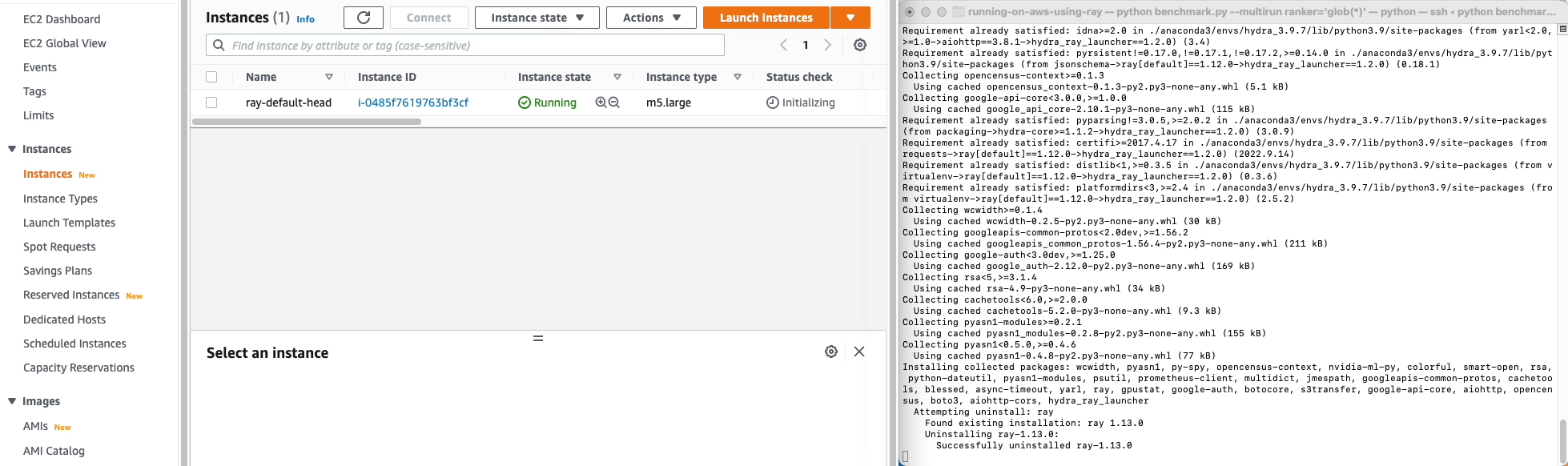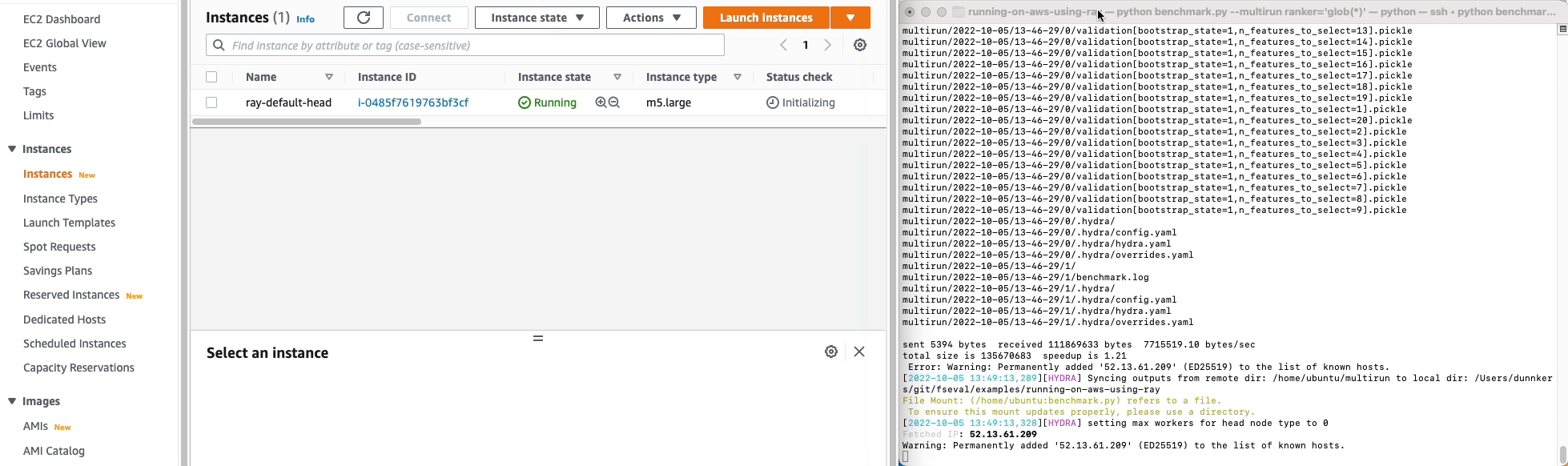
🙌🏻
The results are downloaded back to your local computer, and are available in the results folder:
(base) ➜ running-on-aws-using-ray git:(recipe/running-on-aws) ✗ tree results
results
└── results.sqlite
0 directories, 1 file
In this way, it's possible to run experiments on a massive scale, by using Amazon's datacentres for scaling.
🌐 Sources
For more information, see the following sources: