Metrics
FeatureImportances
✅ Enabled by default.
Exports whatever your ranker sets as feature_importances_ to a table. This can be CSV, SQL, or a WandB table, depending on what is configured as a Callback.
For example, the feature_importances table:
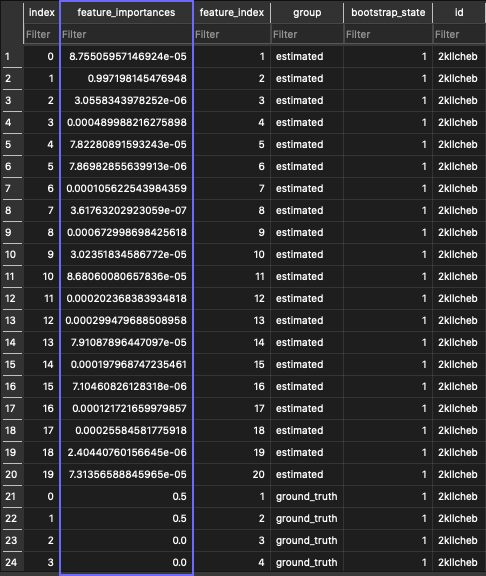
RankingScores
✅ Enabled by default.
Exports the time it took to fit the ranking, in a fit_time variable.
For example, the ranking_scores table:
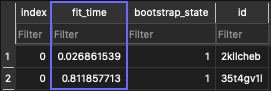
ValidationScores
✅ Enabled by default.
Exports the validation scores to a table. Stores whatever results came out of the validation estimator's score() function. The results are stored per n_features_to_select metric.
For example, the validation_scores table:
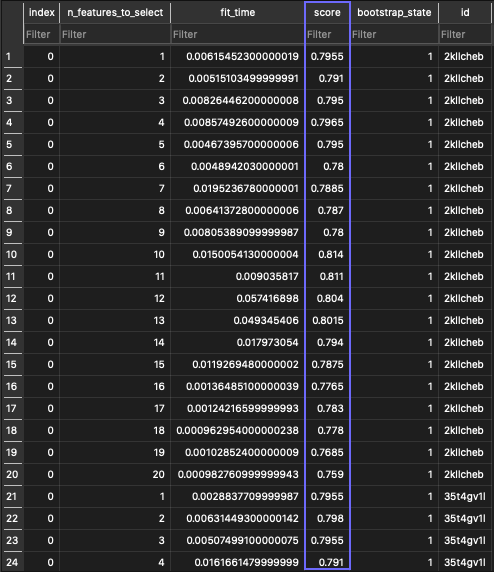
⚙️ Custom Metrics
To add your own custom metric, you can use the AbstractMetric interface.
class AbstractMetric:
def score_bootstrap(
self,
ranker: AbstractEstimator,
validator: AbstractEstimator,
callbacks: Callback,
scores: Dict,
**kwargs,
) -> Dict:
"""Aggregated metrics for the bootstrapped pipeline."""
...
def score_pipeline(self, scores: Dict, callbacks: Callback, **kwargs) -> Dict:
"""Aggregated metrics for the pipeline."""
...
def score_ranking(
self,
scores: Union[Dict, pd.DataFrame],
ranker: AbstractEstimator,
bootstrap_state: int,
callbacks: Callback,
feature_importances: Optional[np.ndarray] = None,
) -> Union[Dict, pd.DataFrame]:
"""Metrics for validating a feature ranking, e.g. using a ground-truth."""
...
def score_support(
self,
scores: Union[Dict, pd.DataFrame],
validator: AbstractEstimator,
X,
y,
callbacks: Callback,
**kwargs,
) -> Union[Dict, pd.DataFrame]:
"""Metrics for validating a feature support vector. e.g., this is an array
indicating yes/no which features to include in a feature subset. The array is
validated by running the validation estimator on this feature subset."""
...
def score_dataset(
self, scores: Union[Dict, pd.DataFrame], callbacks: Callback, **kwargs
) -> Union[Dict, pd.DataFrame]:
"""Aggregated metrics for all feature subsets. e.g. 50 feature subsets for
p >= 50."""
...
def score_subset(
self,
scores: Union[Dict, pd.DataFrame],
validator: AbstractEstimator,
X,
y,
callbacks: Callback,
**kwargs,
) -> Union[Dict, pd.DataFrame]:
"""Metrics for validation estimator. Validates 1 feature subset."""
...
For example, this is how the RankingScores metric is implemented:
from typing import Dict
from fseval.types import AbstractEstimator, AbstractMetric, Callback
class UploadRankingScores(AbstractMetric):
def score_bootstrap(
self,
ranker: AbstractEstimator,
validator: AbstractEstimator,
callbacks: Callback,
scores: Dict,
**kwargs,
) -> Dict:
ranking_scores = scores["ranking"]
## upload ranking scores
callbacks.on_table(ranking_scores, "ranking_scores")
return scores
With its according config file:
# @package metrics
ranking_scores:
_target_: fseval.metrics.ranking_scores.UploadRankingScores
And can then be activated on the commandline with +metrics='[ranking_scores]'.