Callbacks
Callbacks are responsible for storing the experiment config and results. Any callback can be used on its own, but multiple callbacks can also be used at the same time.
To CSV
class fseval.config.callbacks.ToCSVCallback(
dir: str=MISSING,
mode: str="a",
)
CSV support for fseval. Uploads general information on the experiment to a experiments table and provides a hook for uploading custom tables.
By default, four .csv files are created:
/Users/dunnkers/Downloads/fseval_csv_results_dir
├── experiments.csv
├── feature_importances.csv
├── ranking_scores.csv
└── validation_scores.csv
0 directories, 4 files
💡 More tables or metrics can be configured using Custom metrics.
Attributes:
dir : str | The directory to save all CSV files to. For example, in this directory a file experiments.csv will be created, containing the config of all experiments that were run. |
mode : str | Whether to overwrite or append. Use "a" for appending and "w" for overwriting. |
Use with +callbacks='[to_csv]' +callbacks.to_csv.dir=<save_dir> on the commandline, or:
defaults:
- base_pipeline_config
- _self_
- override /callbacks:
- to_csv
callbacks:
to_csv:
dir: <save_dir>
To SQL
class fseval.config.callbacks.ToSQLCallback(
url: str=MISSING,
kwargs: Dict=field(default_factory=lambda: {}),
if_table_exists: str="append"
)
SQL support for fseval. Achieved through integration with SQLAlchemy. Uploads general information on the experiment to a experiments table and provides a hook for uploading custom tables.
For example, by default the following four tables are uploaded:
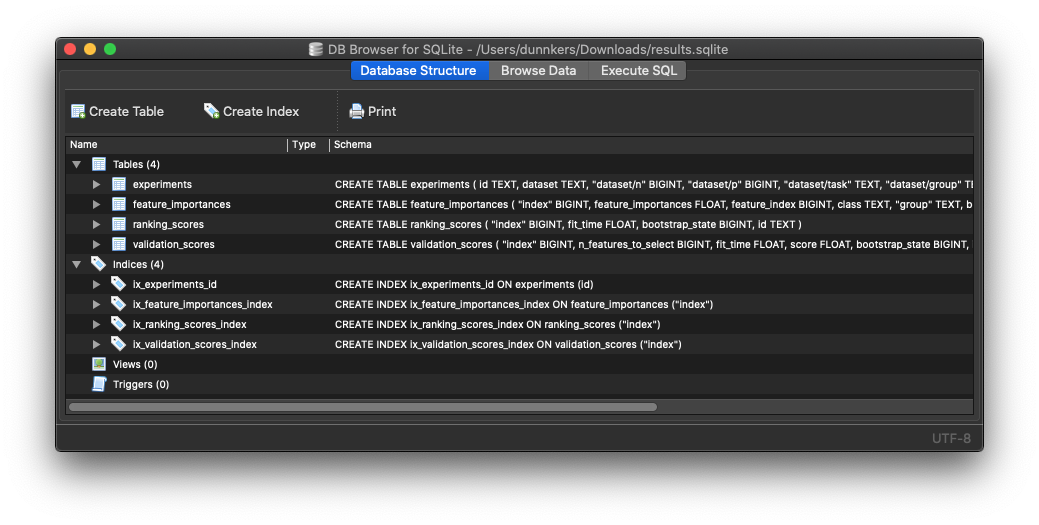
experimentscontains an entry for each ran experiment. Contains a column for a local path,feature_importancescontains the estimated feature importances - given the ranker estimates them. Created by the FeatureImportances metric.ranking_scorescontains the fitting time for each ranker fit. Created by the RankingScores metric.validation_scorescontains the validation estimator scores, for each feature subset that was evaluated. Created by the Validation Scores metric.
💡 More tables or metrics can be configured using Custom metrics.
Attributes:
url : str | The database URL. Is of type RFC-1738, e.g. dialect+driver://username:password@host:port/database See the SQLAlchemy documentation for more information; https://docs.sqlalchemy.org/en/14/core/engines.html#database-urls |
kwargs : Dict | All keyword arguments to pass to SQLAlchemy's create_engine function. @see; https://docs.sqlalchemy.org/en/14/core/engines.html#sqlalchemy.create_engine. |
if_table_exists : str | What to do when a table of the specified name already exists. Can be 'fail', 'replace' or 'append'. By default is 'append'. For more info, see the Pandas.DataFrame#to_sql function. |
Use with +callbacks='[to_sql]' +callbacks.to_sql.url=<db_url> on the commandline, or:
defaults:
- base_pipeline_config
- _self_
- override /callbacks:
- to_sql
callbacks:
to_sql:
url: <db_url>
To Weights and Biases
class fseval.config.callbacks.ToWandbCallback(
log_metrics: bool=True,
wandb_init_kwargs: Dict[str, Any]=field(default_factory=lambda: {}),
)
Support for exporting the job config and result tables to Weights and Biases.
The results are stored in wandb Tables. For example, we can create a Custom chart like so:
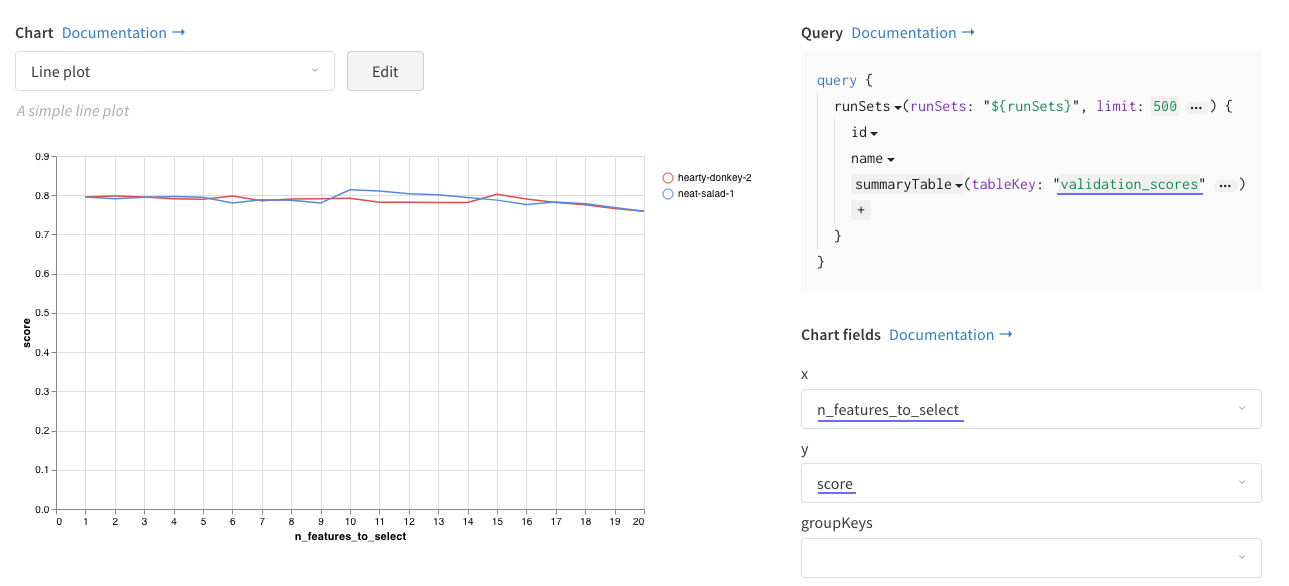
Which then allows us to compare the performance of different algorithms right in the dashboard.
Attributes:
log_metrics : bool | Whether to log metrics. In the case of a resumation run, a user might probably not want to log metrics, but just update the tables instead. |
wandb_init_kwargs : Dict[str, Any] | Any additional settings to be passed to wandb.init(). See the function signature for details; https://docs.wandb.ai/ref/python/init |
Use with +callbacks='[to_wandb]' +callbacks.to_wandb.wandb_init_kwargs.project=new_project on the commandline, or:
defaults:
- base_pipeline_config
- _self_
- override /callbacks:
- to_wandb
callbacks:
to_wandb:
wandb_init_kwargs:
project: my_wandb_project
⚙️ Custom Callbacks
To create a custom callback, implement the following interface:
class Callback(ABC):
def on_begin(self, config: DictConfig):
...
def on_config_update(self, config: Dict):
...
def on_table(self, df: pd.DataFrame, name: str):
...
def on_summary(self, summary: Dict):
...
def on_end(self, exit_code: Optional[int] = None):
...
For example implementations, check the fseval repository fseval/callbacks directory, and its associated yaml configs.